Apache Flink is a powerful stream processing framework that has gained popularity for its ability to handle large-scale data processing in real-time. Flink’s architecture is designed to deliver low-latency, high-throughput, and fault-tolerant data processing.
In this article, we’ll explore the core components of Apache Flink’s architecture, its dataflow programming model, state management, and fault tolerance mechanisms.
Flink Architecture
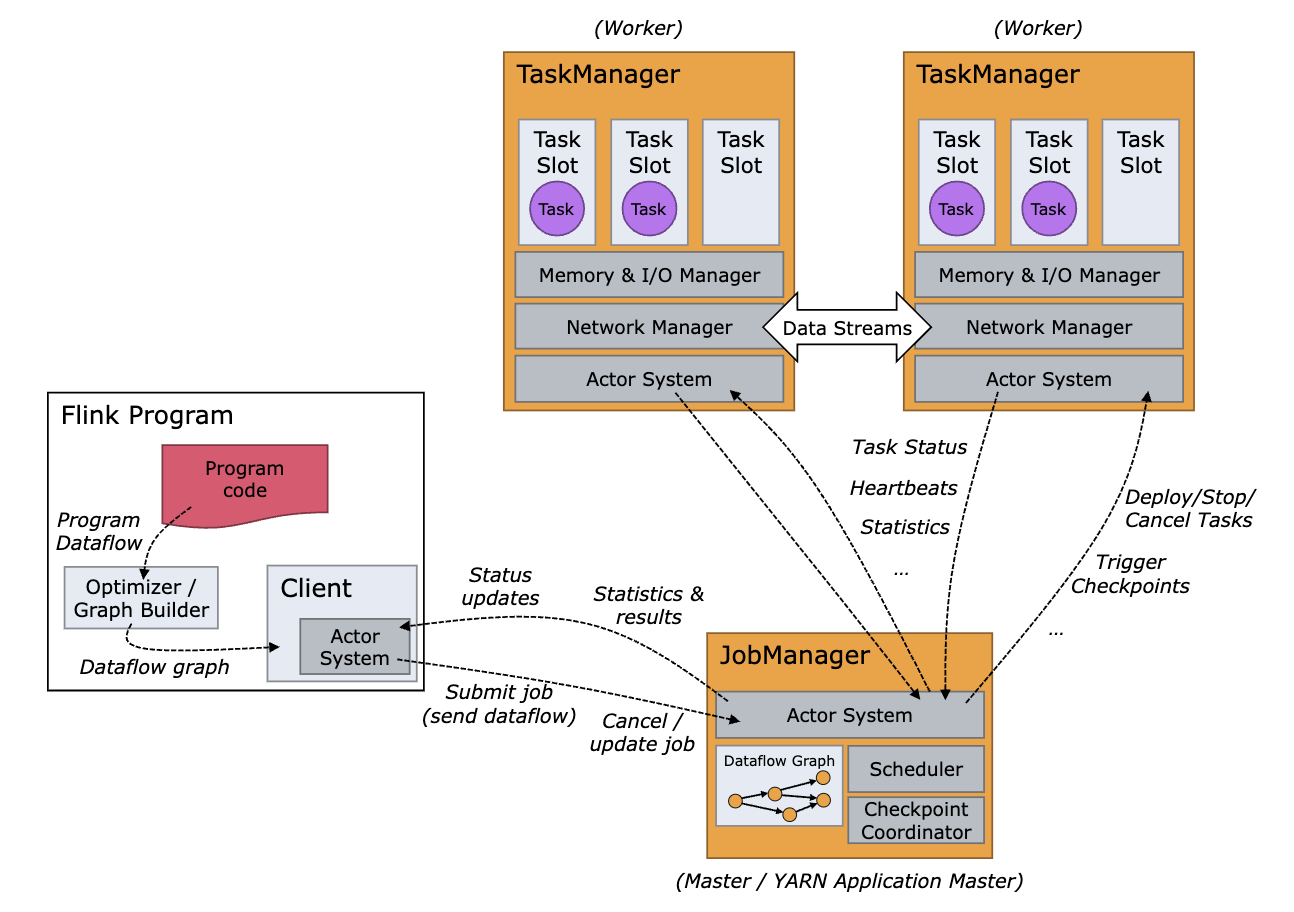 Fig 1. Flink Architecture(source: Flink Docs)
Fig 1. Flink Architecture(source: Flink Docs)
Overview
At the heart of Apache Flink are two main components: the JobManager and the TaskManager.
- The JobManager is the brain of the Flink cluster. It handles job scheduling, manages resources, and coordinates distributed execution. When a job is submitted, the JobManager splits it into individual tasks, schedules them on available TaskManagers, and monitors their execution. It’s also responsible for managing checkpoints and recovering the job in case of failures.
- The TaskManager (also called workers) execute the tasks of a dataflow, and buffer and exchange the data streams. It executes the subtasks that are part of a Flink job. Each TaskManager is assigned a portion of the overall task and handles it using the resources allocated by the JobManager. TaskManagers also manage their local state, handle network communication, and report progress back to the JobManager.
The Client is not part of Flink runtime, but is used to prepare and send a dataflow to the JobManager. After that, the client can disconnect (detached mode), or stay connected to receive progress reports (attached mode). The client runs either as part of the Java/Scala program that triggers the execution, or in the command line process
./bin/flink run ....
JobManager
The JobManager coordinate the distributed execution of Flink Applications: it decides when to schedule the next task (or set of tasks), reacts to finished tasks or execution failures, coordinates checkpoints, and coordinates recovery on failures, among others. This process consists of three different components:
Resource Manager
The ResourceManager responsible for resource de-/allocation and provisioning in a Flink cluster — it manages task slots, which are the unit of resource scheduling in a Flink cluster. Flink implements multiple ResourceManagers for different environments and resource providers such as YARN, Kubernetes and standalone deployments. In a standalone setup, the ResourceManager can only distribute the slots of available TaskManagers and cannot start new TaskManagers on its own.
Dispatcher
Dispatcher provides a REST interface to submit Flink applications for execution and starts a new JobMaster for each submitted job. It also runs the Flink WebUI to provide information about job executions.
JobMaster
JobMaster is responsible for managing the execution of a single JobGraph. Multiple jobs can run simultaneously in a Flink cluster, each having its own JobMaster.
TaskManager
The TaskManagers (also called workers) execute the tasks of a dataflow, and buffer and exchange the data streams.
There must always be at least one TaskManager. The smallest unit of resource scheduling in a TaskManager is a task slot. The number of task slots in a TaskManager indicates the number of concurrent processing tasks.
Task Slot
Flink Operator
Flink’s Operators transform one or more DataStreams into a new DataStream. In simple words, any function which transforms the input stream to a new stream is called an Operator
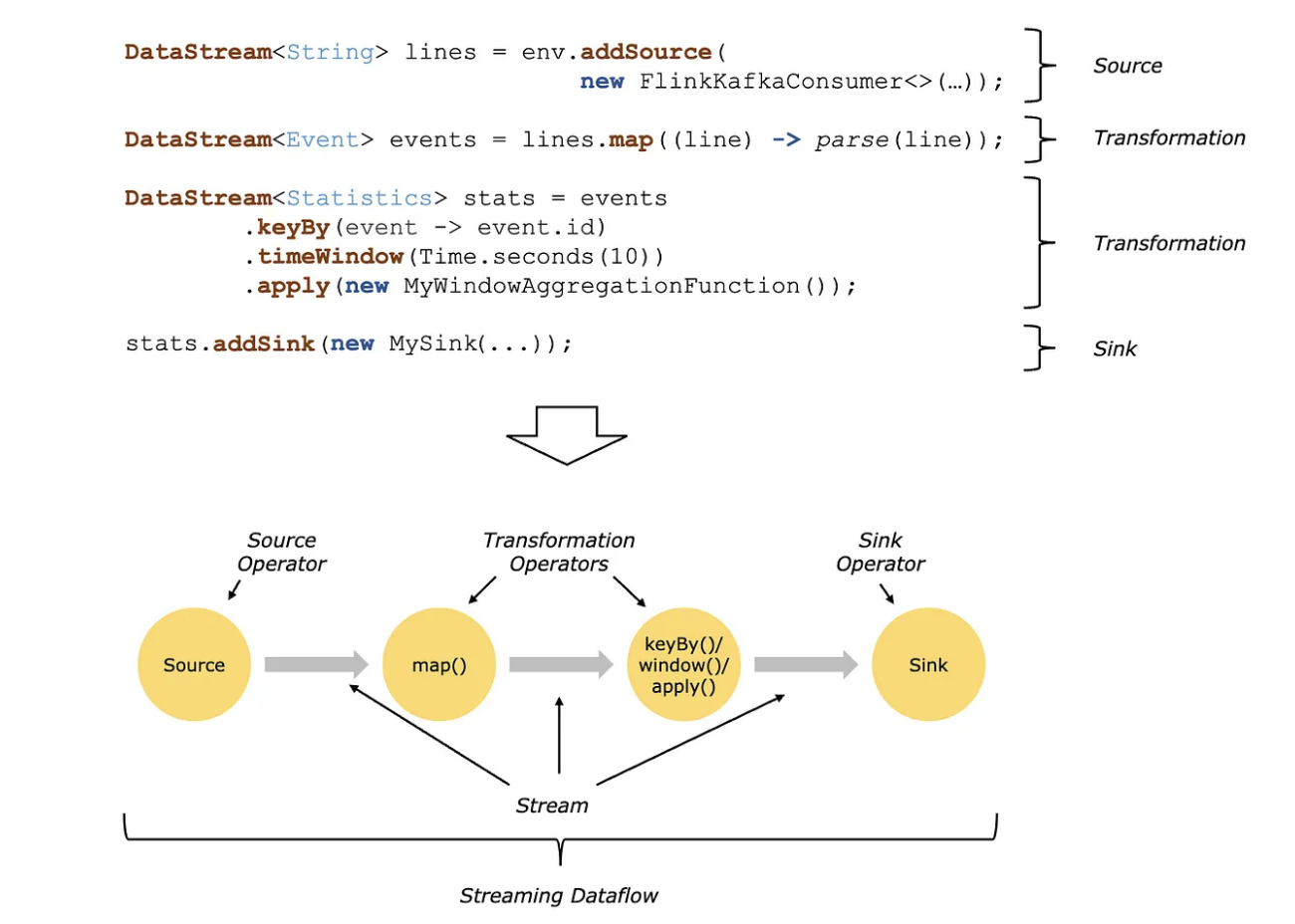 In above image, we are converting the input data stream to a new stream by processing/transforming/filtering it using different functions, all these functions above are classified as “Operators” in Flink.
In above image, we are converting the input data stream to a new stream by processing/transforming/filtering it using different functions, all these functions above are classified as “Operators” in Flink.
Task Slot
Each TaskManager is a JVM process and may execute one or more subtasks in separate threads. To control how many tasks a TaskManager accepts, it has so called task slots (at least one). Each task slot represents a fixed subset of resources of the TaskManager.
A task slot is the smallest unit of resource scheduling in a TaskManager.
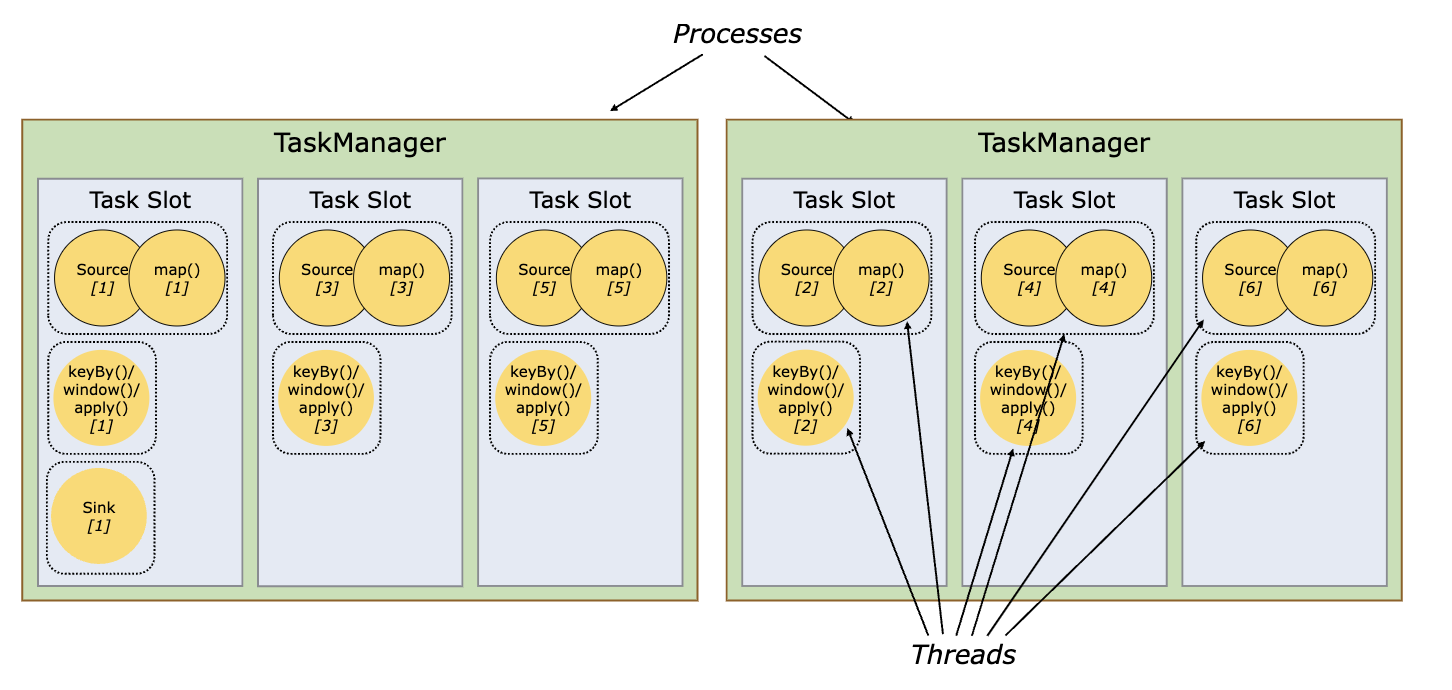
- In the image above, we have 2 Task Managers and 6 Task Slots (3 in each Task Manager).
- These 3 task slots will be competing for resources (memory/CPU) of the Task Manager they are in. Since there are 3 Task Slots, Task Manager will dedicate 1/3 of its managed memory to each slot.
- The
source(),map()functions shown here are our “Operators”. Every operator will have some parallel instances running (referred as operator instance in this post) which is called parallelism of an Operator. In the above image,source()operator has 6 parallel instances running (source[1]….source[6]), distributed among all Task slots in both Task Managers, therefore it’s parallelism = 6 - A Task Slot is like a thread pool with multiple threads running inside it. If you see Task Slot 1 in Task Manager 1, there are 3 threads inside it. Each thread here is called a Task, it’s processing one parallel instance of a Operator or an Operator Chain (we will come to chain part later). {
source()[1],map()[1]} is the operator chain while {sink[1]} is a single operator instance.
Tasks and Operator Chains
For distributed execution, Flink chains operator subtasks together into tasks. Each task is executed by one thread. Chaining operators together into tasks is a useful optimization: it reduces the overhead of thread-to-thread handover and buffering, and increases overall throughput while decreasing latency.
Task Slots and Resources
Each worker (TaskManager) is a JVM process, and may execute one or more subtasks in separate threads. To control how many tasks a TaskManager accepts, it has so called task slots (at least one).
Each task slot represents a fixed subset of resources of the TaskManager. A TaskManager with three slots, for example, will dedicate 1/3 of its managed memory to each slot. Slotting the resources means that a subtask will not compete with subtasks from other jobs for managed memory, but instead has a certain amount of reserved managed memory. Note that no CPU isolation happens here; currently slots only separate the managed memory of tasks.
By adjusting the number of task slots, users can define how subtasks are isolated from each other. Having one slot per TaskManager means that each task group runs in a separate JVM (which can be started in a separate container, for example). Having multiple slots means more subtasks share the same JVM. Tasks in the same JVM share TCP connections (via multiplexing) and heartbeat messages. They may also share data sets and data structures, thus reducing the per-task overhead.
Flink Application Execution Mode
Flink applications can be deployed in 2 mode:
- Application Mode
- Session Mode
Flink Deployment Patterns
Flink is a versatile framework, supporting many different deployment patterns in a mix and match fashion. The available deployment patterns include,
- Standalone
- YARN
- Kubernetes
- Cloud
Standalone
The standalone mode is the most barebone way of deploying Flink. The Flink services such as JobManager and TaskManager are just launched as processes on the operating system. Flink runs on all UNIX like systems e.g. Linux, Mac OS X and Cygwin. Flink requires Java 1.8.x or higher installed.
In Production environments, the Flink clusters have to be deployed for High-availability(HA) to ensure smooth processing. To enable HA for a standalone cluster, you have to use the ZooKeeper HA services. Flink leverages ZooKeeper for distributed coordination between all running JobManager instances.
For more details on the deployment steps, please refer to this link.
Standalone deployment in Flink offers simplicity and flexibility, making it suitable for various use cases ranging from small-scale development and testing environments to large-scale production deployments. However, it also requires manual management of resources and may not provide the same level of resource isolation and multi-tenancy capabilities as other deployment options like YARN or Kubernetes.
YARN
YARN is a popular resource manager for running Hadoop jobs and other data processing applications such as MapReduce, Spark, Storm and Flink, among others. YARN was born out of the idea to separate the concerns of resource management and job scheduling/monitoring.
YARN achieves this with two components
- Resource Manager
- Node Manager.
The Resource Manager accepts jobs from the client and schedules them to be run on the Node Manager. The Node Manager runs the application by creating multiple containers. Apache Flink can be deployed using YARN by creating Flink’s JobManager and TaskManager in such containers. This allows to dynamically allocate and de-allocate TaskManager resources based on the job running.
YARN also allows submitting Flink jobs using the SQL client. This makes it an attractive choice for deploying Apache Flink if there are existing YARN clusters running or if there are plans to use other data processing systems in conjunction with Flink, allowing them to be deployed together. YARN can be scaled up or down depending on the load and provides token based security with Kerberos authentication.
YARN is not particularly a great choice if you are not already in the Apache Hadoop ecosystem since there is a steep learning curve and requires expertise managing the additional configurations and settings, which can be difficult for those who are not familiar with YARN.
Kubernetes
Kubernetes has grown to be the de-facto orchestrator for deploying Cloud Native workloads. Apache Flink comes with a native integration with Kubernetes to deploy Flink. Similar to YARN, the native Kubernetes integration allows to dynamically allocate and de-allocate TaskManager resources based on the job running. Apart from the native integration, there are multiple Kubernetes Operators that allow creation of Flink Jobs declaratively.
The native Kubernetes integration allows running Flink jobs without the hassle of writing YAML files and abstracting the Kubernetes complexity while providing the benefits of Kubernetes such as auto-healing and resource orchestration. This can be a good first step towards running Flink Jobs in Kubernetes while using the same clients for submitting Flink Jobs. Flink also offers High Availability(HA) while deploying using the native Kubernetes integration.
There are multiple open source Kubernetes Operators for Flink such as the official Apache Flink Operator, Flinkk8soperator by Lyft and the Flink on Kubernetes operator by Spotify. These operators allow declaratively defining the Flink cluster and creating Flink Jobs using a Custom Resource in Kubernetes. This implies, Flink Jobs can be natively managed using Kubernetes clients and operational governance can be implemented with GitOps.
While there are several advantages to deploying Flink on Kubernetes such as high availability and scalability, it requires expertise in running and maintaining a Kubernetes cluster along with ensuring the Flink applications are fault tolerant with appropriate recovery mechanisms.
Cloud
Fully managed services abstract away much of the complexity involved in deploying and managing Apache Flink clusters. Users don’t need to worry about infrastructure provisioning, cluster configuration, or software updates, as these tasks are handled by the managed service provider. Deploy highly available and durable applications with Multi-AZ deployments and APIs for application lifecycle management.
Managed services provide built-in monitoring and logging capabilities, allowing users to easily track the performance and health of their Flink applications. It also offers enhanced security features, such as encryption, access controls, and compliance certifications. Finally, managed services integrate seamlessly with other cloud services and data processing tools, allowing users to build end-to-end data pipelines more easily.